你是不是经常听到"大数据"这个词,但一说到具体用什么工具就懵了?别担心,今天咱们就来聊聊这个事儿。大数据听起来高大上,其实说白了就是处理海量信息的技术,而软件就是干这活儿的"工具人"咱们一个个来看,保证让你看完心里有数。
一、大数据到底需要啥软件?
先搞清楚一个概念:大数据处理不是单一软件能搞定的,它需要一套组合拳。就像做菜,你得有刀、有锅、有调料对吧?大数据软件也分好几类:
1.
存储类
:相当于冰箱,专门存数据
2.
计算类
:相当于厨师,负责处理数据
3.
分析类
:相当于美食家,负责品鉴数据
4.
可视化类
:相当于摆盘师傅,让数据好看
二、存储类软件:数据的家
Hadoop HDFS
这算是大数据界的"老大哥"了,2006年就出来了。简单理解就是个超级大仓库,能把数据分散存放在很多台电脑上。比如淘宝每天产生的用户数据,就是靠这类系统存着的。
特点
:
- 便宜(用普通电脑就能组集群)
- 可靠(坏一两台电脑数据也不会丢)
- 扩展性强(数据多了加电脑就行)
不过说实话,现在直接用HDFS的少了,更多是用它的升级版或者替代品。
其他存储选择
-
HBase
:适合快速查询,比如微信消息记录 -
Cassandra
:适合全球分布的数据,像跨国公司的用户信息 -
MongoDB
:适合半结构化数据,比如社交媒体的帖子
三、计算类软件:数据的加工厂
Spark
这是现在的当红炸子鸡!比Hadoop快得多,据说内存计算能快100倍。想象一下,你要在10亿条记录里找符合条件的数据,Spark可能几分钟就搞定了。
为啥这么牛
:
- 内存计算(少读写硬盘)
- 支持多种语言(Python、Java都能用)
- 生态丰富(机器学习、图计算都能做)
有个真实案例,某银行用Spark把风险分析从4小时缩短到7分钟,省了多少人力物力啊。
其他计算引擎
-
Flink
:适合实时数据处理,比如滴滴的实时调度 -
Storm
:早期的流处理框架,现在用得少了 -
Presto
:适合交互式查询,像分析师随时查数据
四、分析类软件:数据的侦探
Hadoop MapReduce
虽然计算速度被Spark吊打,但MapReduce的思想特别重要。它把大任务拆成小任务,这个思路影响了很多后来者。
举个栗子,要统计全国各城市销售额,MapReduce会:
1. 先把数据按城市分组(Map)
2. 然后分别计算每个城市的和(Reduce)
机器学习工具
-
TensorFlow
:谷歌出的,适合深度学习 -
PyTorch
:Facebook出的,研究人员最爱 -
Mahout
:传统机器学习算法库
个人觉得,现在做数据分析不会点机器学习都不好意思说自己是搞大数据的,但千万别被唬住,很多场景用简单算法就够用了。
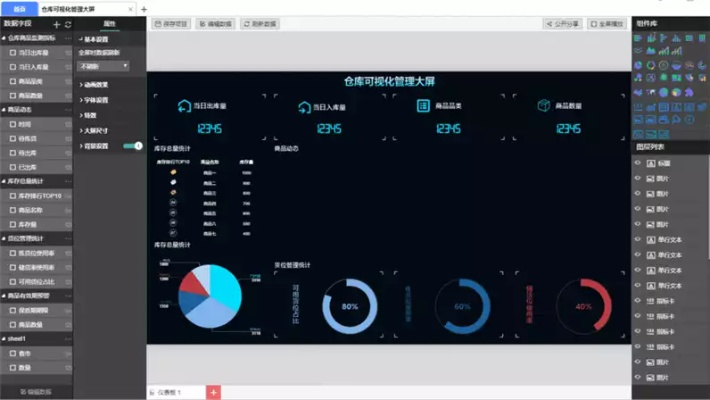
五、可视化软件:数据的化妆师
Tableau
这个真心推荐新手试试,拖拖拽拽就能出漂亮图表。某零售公司用它发现了"尿布和啤酒"的经典关联销售案例——年轻爸爸们买尿布时会顺手买啤酒。
优点
:
- 操作简单
- 图表专业
- 支持多种数据源
其他选择
-
Power BI
:微软出的,和Office系列配合好 -
ECharts
:百度开源,适合网页嵌入 -
Superset
:Airbnb开源的,技术控最爱
六、全家桶解决方案
不想自己搭积木?这些打包方案适合你:
1.
Cloudera
:企业级Hadoop发行版
2.
Hortonworks
:另一个Hadoop发行版(现在和Cloudera合并了)
3.
AWS EMR
:亚马逊云的大数据服务
4.
阿里云MaxCompute
:国内企业常用
说实话,现在中小企业直接用云服务更划算,自己维护集群太费劲了。
七、怎么选软件?
看到这儿你可能要问:这么多我该学哪个?我的建议是:
1.
看需求
:要是做实时分析,就别学MapReduce了
2.
看团队
:同事都用Python就别非学Java系的
3.
看趋势
:Spark、Flink这些新兴的更值得投入
4.
别贪多
:精通一两个比啥都懂点强
有个误区得提醒:不是工具越新越好。我见过不少公司追新技术反而把项目搞黄的案例。
八、学习路线建议
如果你是小白,可以这么入手:
1. 先装个
Hadoop
单机版感受下
2. 学
Spark
的Python接口(PySpark)
3. 用
Jupyter Notebook
做数据分析
4. 最后玩
Tableau
可视化
记住,大数据工具只是手段,
解决业务问题才是目的
。见过太多人沉迷技术却忘了为啥要用它。
最后说句掏心窝的话:这行变化快,但核心思想变化慢。把基础打牢,新工具来了也能快速上手。现在网上教程很多,别被吓住,大数据软件说白了就是帮人处理数据的工具,会用螺丝刀的人不一定比会用锤子的厉害,关键看你能不能用工具做出好东西来。